
Description
I chanced upon a tool known as opengrep which was forked from semgrep. It is a static analysis tool which could scan files for pattern (much like grep but on steroids). The binary is released in the Github which was what prompt me to choose opengrep over semgrep.
I decided to hunt low hanging fruits that uses system function call as well as basic integer over and underflow patterns. After some time of code review, I was not able to find any integer over or underflow but it was still quite the ride. From thinking I found a vulnerability to finding out that it was not exploitable.
Steps Taken during Static Code Review
The following are the steps that I had in mind when reviewing for integer overflow and underflows:
- Select a target
- Look for patterns for dangerous functions
- Look for
sizevariables - Check if
sizeis attacker controlled - Trace the function call to see where
sizecomes from - Check maximum allocation size against memory limits
The Target
For the experiment, the selected target was Accel-PPP v 1.13.0
The Rule
The rules are written in YAML. There are many references that we can refer to from opengrep-rules Github here. From there, I have come up the following:
- Search for any pattern with system function call.
- Potential integer wraparound searching for expressions that might have some form of addition or subtraction with inequalities via regex
- Refer to Annex for breakdown of the regex used at the point of experimentation
- Common sinks that we might want to look out for.
rules:
- id: dangerous-system-usage
languages: [c]
severity: WARNING
message: >
Potential command injection. check for controllable inputs.
Verify that the strings are not controllable and even if controllable that it is sanitized
patterns:
- pattern: |
system( $X );
metadata:
category: correctness
- id: potential-integer-wraparound
languages: [c]
severity: WARNING
message: >
Possible integer overflow or underflow detected before an equality check.
patterns:
- pattern-regex: "\\b[\\w)\\]]+\\s*[\\+\\-]\\s*[\\w(\\[]+\\s*[<>!=]=?\\s*[\\w(\\[]+"
fix: >
Use full strings and limit buffer to the size of allocated buffer at least
- id: dangerous-function-usage
languages: [c, cpp]
severity: WARNING
message: >
This function is known to cause buffer overflows if not used carefully.
Consider using safer alternatives like strncpy, snprintf, or memcpy with bounds checking.
metadata:
references:
- https://cwe.mitre.org/data/definitions/120.html # Buffer Overflow
- https://cwe.mitre.org/data/definitions/676.html # Unsafe Function Use
patterns:
- pattern-either:
- pattern: memcpy(...)
- pattern: strcpy(...)
- pattern: strcat(...)
- pattern: sprintf(...)
- pattern: gets(...)
- pattern: scanf(...)
- pattern: sscanf(...)
- pattern: gets_s(...)
- pattern: strncpy(...) # Only flag if used improperly
fix: Consider using safer alternatives like strncpy, snprintf, or checking bounds before usage.Running OpenGrep
The following command was used to run against the target code base. We can make use of the output format SARIF. This SARIF format is crucial for quickly jumping to different points of the source code based on the rule hits.
Run script
#! /bin/bash
# First parameter would be the path to the code base
# Using the hunt.yaml rule that I have created for the experimentation
# Make use of SARIF viewer in Visual Studio Code and open the code base together
./opengrep scan --config rules/hunt.yaml $1 --sarif-output=output.sarifRun output
We should be able to see the progress of the scan followed by the output in the terminal. By the end of the scan, we would obtain the output.sarif file. Notice that there are accompanying line number as well as location of the code where the rule hits. In this run, there are 409 findings of which there were only some that caught my attention with no hits that seem to be exploitable.
$ ./run.sh accel-ppp/
┌──────────────┐
│ Opengrep CLI │
└──────────────┘
Scanning 378 files (only git-tracked) with 3 Code rules:
CODE RULES
Language Rules Files Origin Rules
────────────────────────── ────────────────
c 3 213 Custom 3
cpp 1 83
PROGRESS
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:14
...
...
...
...
accel-ppp/accel-pppd/triton/mempool.c
❯❱ rules.potential-integer-wraparound
Possible integer overflow or underflow detected before an equality check.
▶▶┆ Autofix ▶ Use full strings and limit buffer to the size of allocated buffer at least
115┆ if (mmap_ptr + size >= mmap_endptr) {
⋮┆----------------------------------------
▶▶┆ Autofix ▶ Use full strings and limit buffer to the size of allocated buffer at least
236┆ if (it->timestamp + DELAY < time(NULL)) {
accel-ppp/accel-pppd/triton/triton.c
❯❱ rules.dangerous-function-usage
This function is known to cause buffer overflows if not used carefully. Consider using safer
alternatives like strncpy, snprintf, or memcpy with bounds checking.
▶▶┆ Autofix ▶ Consider using safer alternatives like strncpy, snprintf, or checking bounds before usage.
140┆ memcpy(thread_frame - thread->ctx->uc->uc_stack.ss_size, thread->ctx->uc->uc_stack.ss_sp,
thread->ctx->uc->uc_stack.ss_size);
⋮┆----------------------------------------
▶▶┆ Autofix ▶ Consider using safer alternatives like strncpy, snprintf, or checking bounds before usage.
485┆ memcpy(uc->uc_stack.ss_sp, frame, stack_size);
accel-ppp/accel-pppd/utils.c
❯❱ rules.dangerous-function-usage
This function is known to cause buffer overflows if not used carefully. Consider using safer
alternatives like strncpy, snprintf, or memcpy with bounds checking.
▶▶┆ Autofix ▶ Consider using safer alternatives like strncpy, snprintf, or checking bounds before usage.
51┆ sprintf(str, "%i.%i.%i.%i", (addr >> 24) & 0xff, (addr >> 16) & 0xff, (addr >> 8) & 0xff,
addr & 0xff);
⋮┆----------------------------------------
▶▶┆ Autofix ▶ Consider using safer alternatives like strncpy, snprintf, or checking bounds before usage.
197┆ memcpy(buf, str, len);
⋮┆----------------------------------------
▶▶┆ Autofix ▶ Consider using safer alternatives like strncpy, snprintf, or checking bounds before usage.
222┆ memcpy(buf, str, len);
accel-ppp/accel-pppd/vlan-mon/vlan_mon.c
❯❱ rules.dangerous-function-usage
This function is known to cause buffer overflows if not used carefully. Consider using safer
alternatives like strncpy, snprintf, or memcpy with bounds checking.
▶▶┆ Autofix ▶ Consider using safer alternatives like strncpy, snprintf, or checking bounds before usage.
417┆ sprintf(svid_str, "%i", svid);
⋮┆----------------------------------------
▶▶┆ Autofix ▶ Consider using safer alternatives like strncpy, snprintf, or checking bounds before usage.
418┆ sprintf(cvid_str, "%i", cvid);
┌──────────────┐
│ Scan Summary │
└──────────────┘
Some files were skipped or only partially analyzed.
Scan was limited to files tracked by git.
Partially scanned: 44 files only partially analyzed due to parsing or internal Opengrep errors
Ran 3 rules on 213 files: 409 findings.Let the Review Begin
SARIF Viewer in Visual Studio Code
There is an extension called “SARIF Viewer” by Microsoft DevLabs that can be found from the extension tab.
With the code base and SARIF output file opened in Visual Studio Code, we can see that jumping from one hit to another hit is painless compared to viewing the JSON content when opened in an editor.
The following shows us the difference between having SARIF Viewer and not having it.
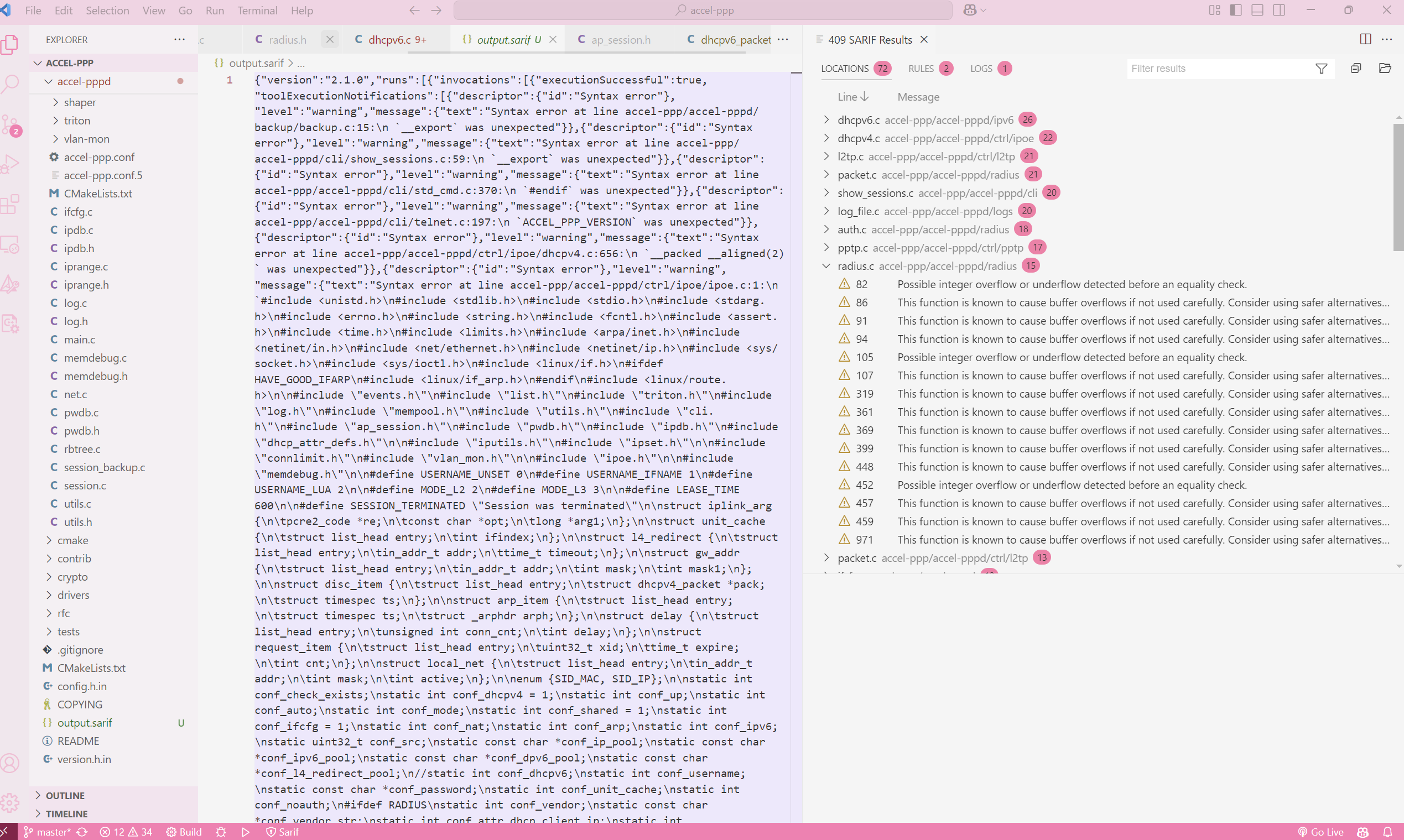
With that, we can easily navigate between different entries. We can even find locations based on the rules.
The next section shows the analysis of a sample promising but false positive example
False Positives Example #1 - (dhcpv6_packet_parse)
At first glance, the following code appears vulnerable to a heap buffer overflow due to missing upper-bound validation on size. Furthermore, the function name suggest high impact if remote attack might be possible.
It looks promising:
- If
sizeis arbitrary,_malloc(sizeof(*pkt) + size)could integer overflow, leading to a small allocation. - Since
memcpy(pkt->hdr, buf, size)writessizebytes, an attacker could cause an out-of-bounds heap write. - There is only a minimum size check (
size < sizeof(struct dhcpv6_msg_hdr)), but no upper-bound check.
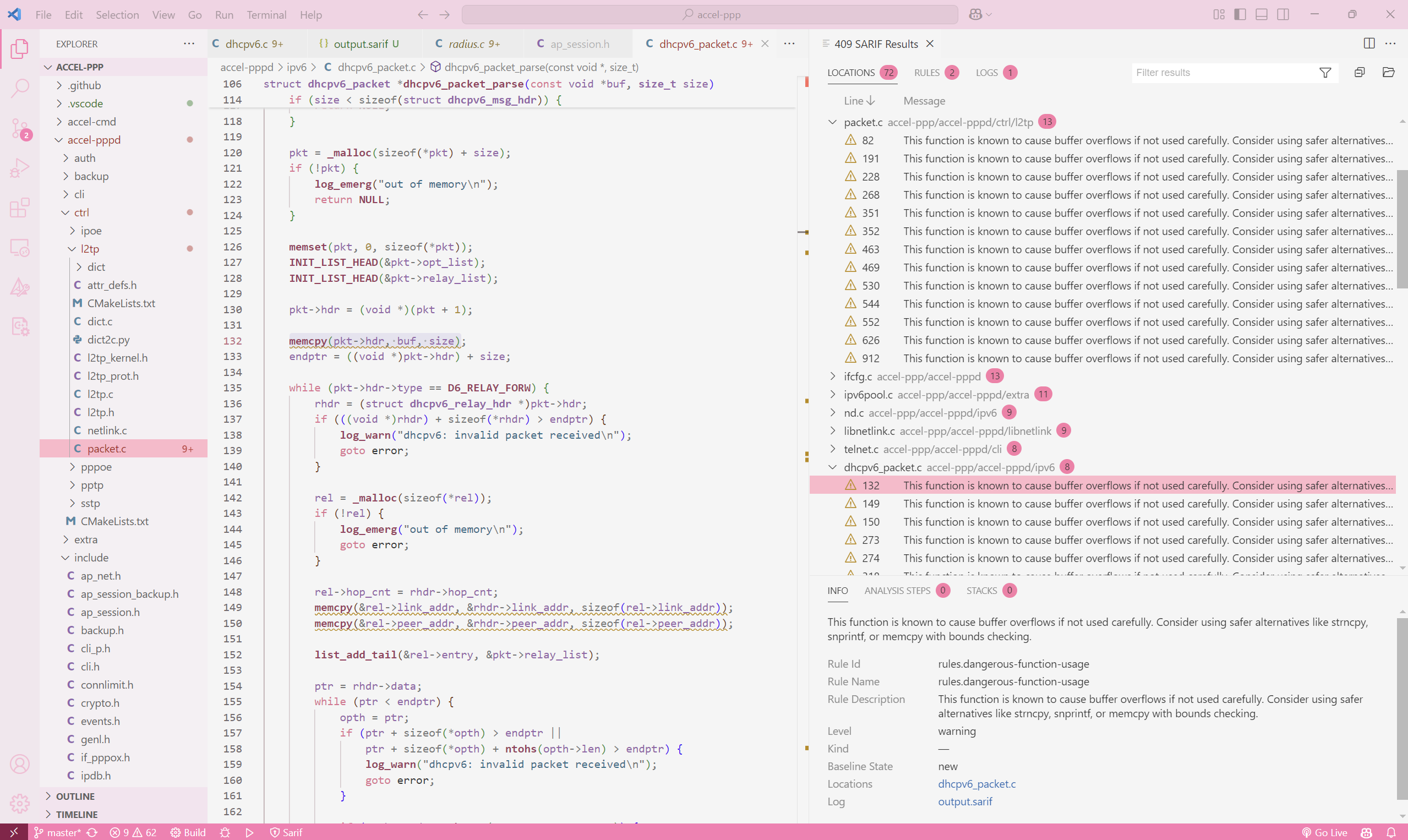
For brevity, here is the snippet for the false positive:
struct dhcpv6_packet *dhcpv6_packet_parse(const void *buf, size_t size)
{
struct dhcpv6_packet *pkt;
struct dhcpv6_opt_hdr *opth;
struct dhcpv6_relay *rel;
struct dhcpv6_relay_hdr *rhdr;
void *ptr, *endptr;
if (size < sizeof(struct dhcpv6_msg_hdr)) {
if (conf_verbose)
log_warn("dhcpv6: short packet received\n");
return NULL;
}
pkt = _malloc(sizeof(*pkt) + size);
if (!pkt) {
log_emerg("out of memory\n");
return NULL;
}
...
...
pkt->hdr = (void *)(pkt + 1);
memcpy(pkt->hdr, buf, size); // Potential overflow?
...
...However, further analysis reveals that size is constrained by the caller to a maximum of BUF_SIZE (65536), making this a false positive.
#define BUF_SIZE 65536
..
...
static int dhcpv6_read(struct triton_md_handler_t *h)
{
...
while (1) {
n = net->recvfrom(h->fd, buf, BUF_SIZE, 0, (struct sockaddr *)&addr, &len);
if (n == -1) {
if (errno == EAGAIN)
break;
log_error("dhcpv6: read: %s\n", strerror(errno));
continue;
}
...
pkt = dhcpv6_packet_parse(buf, n); // n is at most 65536
...
}
_free(buf);
return 0;
}Therefore this is a false positive since:
sizeis at most 65536,_malloc(sizeof(*pkt) + size)cannot overflow.- The maximum memory allocated is ~
65536 + sizeof(*pkt)(safe withinmalloclimits)**. - No heap buffer overflow occurs, because
memcpyalways operates within allocated bounds.
False Positive Example #2 (telnet_send)
This function telnet_send looks really delicious as well since this could potentially be a remote attack if exploitation is possible. The snippets for this function has been provided below:
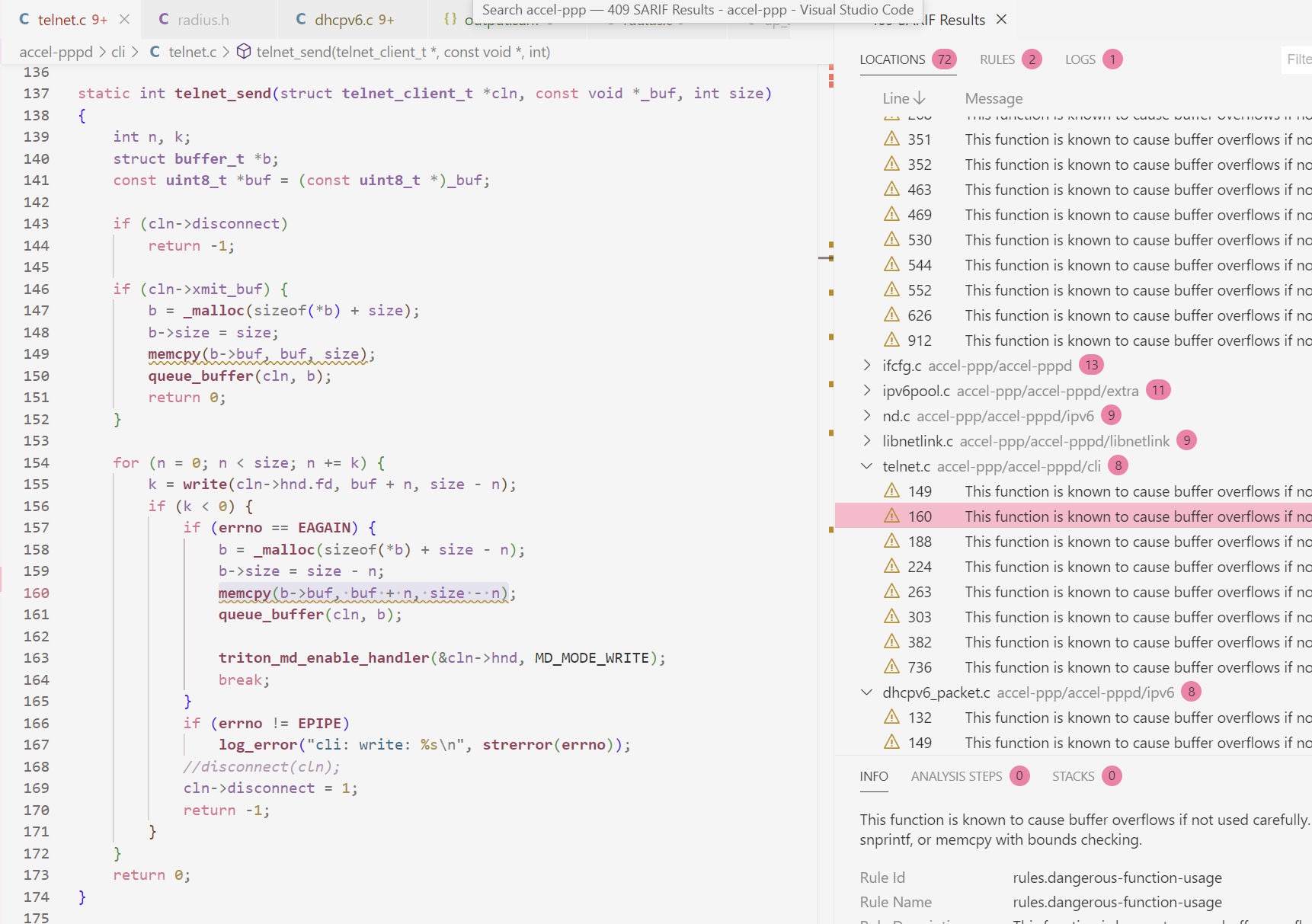
It is promising again as there are two locations where memcpy exists.
[1] shows that if size can be controlled, then we might be able to overflow, causing malloc to allocate small number of bytes while many bytes can be copied, leading to heap overflow.
[2] is another location however, it has a really similar concept to the first one. If size is very huge at first, it can cause an overflow of the malloc size, leading to small allocation while copying a huge number of bytes leading to heap corruption. This problem occurs when the write() fails (EAGAIN).
struct buffer_t {
struct list_head entry;
int size;
struct buffer_t *p_buf;
uint8_t buf[0];
};
...
...
...
static int telnet_send(struct telnet_client_t *cln, const void *_buf, int size)
{
int n, k;
struct buffer_t *b;
const uint8_t *buf = (const uint8_t *)_buf;
if (cln->disconnect)
return -1;
if (cln->xmit_buf) {
b = _malloc(sizeof(*b) + size); // [A]
b->size = size;
memcpy(b->buf, buf, size); // [1]
queue_buffer(cln, b);
return 0;
}
for (n = 0; n < size; n += k) {
k = write(cln->hnd.fd, buf + n, size - n);
if (k < 0) {
if (errno == EAGAIN) {
b = _malloc(sizeof(*b) + size - n); // [B]
b->size = size - n;
memcpy(b->buf, buf + n, size - n); // [2]
queue_buffer(cln, b);
triton_md_enable_handler(&cln->hnd, MD_MODE_WRITE);
break;
}
if (errno != EPIPE)
log_error("cli: write: %s\n", strerror(errno));
//disconnect(cln);
cln->disconnect = 1;
return -1;
}
}
return 0;
}There are many locations where telnet_send function is called. There are numerous that has fixed hardcoded size, while there are some that are dependent on buffer that was passed in.
In send_password_request, buf0 and buf1 buffers are not huge enough to overflow and therefore this does not work.
static int send_password_request(struct telnet_client_t *cln)
{
uint8_t buf0[] = {IAC, WILL, TELOPT_ECHO};
uint8_t buf1[] = "Password: ";
if (telnet_send(cln, buf0, sizeof(buf0)))
return -1;
if (telnet_send(cln, buf1, sizeof(buf1)))
return -1;
return 0;
}The send_prompt is also not interesting because the length is too small for an overflow
static int send_prompt(struct telnet_client_t *cln)
{
sprintf((char *)temp_buf, "%s%s# ", conf_cli_prompt, ap_shutdown ? "(shutdown)" : "");
return telnet_send(cln, temp_buf, strlen((char *)temp_buf));
}In send_cmdline_tail, it looks interesting because the size that is passed to telnet_send is dependent on calculation of cln->cmdline_len and cln->cmdline_pos.
static int send_cmdline_tail(struct telnet_client_t *cln, int corr)
{
if (telnet_send(cln, cln->cmdline + cln->cmdline_pos, cln->cmdline_len - cln->cmdline_pos))
return -1;
memset(temp_buf, '\b', cln->cmdline_len - cln->cmdline_pos - corr);
if (telnet_send(cln, temp_buf, cln->cmdline_len - cln->cmdline_pos - corr))
return -1;
return 0;
}However, the size are constrained are constrained to #define RECV_BUF_SIZE 1024 and therefore it does not work.
Conclusion
Though I did not find any bugs, I found that this method of writing rules to hunt and viewing the output with SARIF Viewer has been enjoyable and quite the experience. Definitely have fun and would try it again on more code bases to see if I can find any. Would be worth the time to expand to other bug classes when I have more time. :D
Annex
Pattern Explanation for Rule
Filtering types of Conditional Statements
Since I want to look quickly for low hanging fruits, I wanted to find some expressions to review. Not all types of expressions would be looked at due to the sheer number of conditional statements. The following are some examples that I wanted to look at first:
- Expression including addition or subtraction on the left hand side followed by inequality within the if statement
Example of condition statements I want to look at:
x + y < 100
a - b >= threshold
arr[i] + 5 == value
(counter - 1 != 0)
x + y < aExamples of condition statements I do not want to look at yet:
if (x) // No `+` or `-`
if (struct->field) // No `+`, `-`, `<`, `>`
if (!flag) // No `+` or `-`
if (func_call()) // No `+`, `-`, `<`, `>`Creating the Regex Expression
\b[\w)\]]+ Matches any variable, number, or closing bracket/parenthesis before + or -. Ensures we are not capturing unary operators (-x).
\s*[\+\-\*]\s* Matches + or - or * with optional spaces around them.
[\w(\[]+ Matches another variable, number, or opening bracket/parenthesis after + or -.
\s*[<>!=]=?\s* Matches comparison/equality operators (<, >, <=, >=, ==, !=) with optional spaces.
[\w(\[]+ Ensures that a variable or number appears after the comparison operator.
REGEX for potential integer over or underflow
The following regex was tested in regex101.
if\s*\([^)]*\b[\w)\]]+\s*[\+\-\*]\s*[\w(\[]+\s*[<>!=]=?\s*[\w(\[]+\s*\)+